Return to Miriam's island
12 Jun 2013In the previous episode we told the story of how we were able to run Miriam’s risk computation. In this episode we will explain what happened in the hazard part, and how we were able to reduce the running time of the hazard calculation from 7 hours to 7 minutes. Please, stay tuned!
The situation so far
In part one we saw that in order to run the risk computation efficiently, we had to change the way the aggregation of the ground motion fields was performed: instead of doing it each time in the risk calculation, we did it once for all at the end of the hazard calculation, by storing the results in an intermediate table. This solution was not satisfactory for at least three reasons:
- we were doubling the needed disk space;
- the hazard computation had become longer for the sake of risk, even if there are cases when you want to perform a pure hazard computation without an associated risk
- the table structure had become more complex and more difficult to grasp and to maintain.
On top of that, the hazard computation had at least two very serious problems:
-
the parallelization worked per sources: in the case of Miriam’s island we had only 6 sources, so we were using only 6 cores, i.e. we were wasting 250 cores of our new and shiny cluster and the total runtime was close to the one you could get on a powerful laptop;
-
the export of the generated ground motion fields was terribly slow, of the order of several days even for simple computation running in few hours and even when exporting relatively small datasets.
Both were known problems, which have been left unsolved for nearly one year, since they were rather tricky and required substantial changes to the event based calculator. But since the release of version 1.0 of the engine was approaching, we decided to invest the time and the resources to finally solve them, as well as to fix the situation with the GMF tables, i.e. the tables used to store the ground motion fields, which had yet another issue:
- the GMF tables (both the original one and the new one containing the
aggregated GMFs) were not normalized in database parlance: in
particular a table with the sites associated to a given hazard
calculation was missing and locations were stored directly in the
GMF tables, not in the
hazard_sitetable.
What was done
The lack of a site table, apart from the data duplication issue, made the risk calculation more complicated than needed. With a site table, it would have been possible to split the complication in two: first, we could have split the risk assets in chunks, by associating them with the closest hazard site, then we could have retrieved the ground motion values only for the reference site of the given chunk. Without the site table everything needed to be performed in a single hypercomplex query. A situation difficult for us as developers, but also difficult to explain and to plot. With the site table, instead, it would have been easy to plot the associations risk assets -> hazard sites and to explain the algorithm to third parties. And since openness and communication are important to GEM we decided to take the necessary steps to fix the database structure. The decision was taken once we realized that with a site table it would have been possible to avoid the very tricky aggregation by location, which gave us all kind of troubles.
Since this was a nontrivial task, we started from the problem that could be addressed without touching the database structure. The problem was to change the parallelization mechanism to take advantage of all cores. There was already a proposal to fix the issue: to parallelize also by stochastic event sets, not only by sources. The idea was simple, but its practical implementation was difficult because we had lots of tests checking the correctness of the previous implementation and we had to change all of them. Also, the distribution mechanism used in the event based core calculator was tricky to use correctly. Therefore, after several failed attempts, we decided not to use the distribution mechanism of the other calculators, but to switch to the distribution mechanism used in the postprocessing phase, which was simpler. Having taken that decision, the change become possible, and it was a matter of fighting the tests to make all of them pass. Then we had the satisfaction of seen the cluster taking advantage of all his cores, passing from 6 to 256 cores, therefore with a speedup of a factor of 40, which means passing from hours of computations to minutes.
Made more confident by this success, then we went on to tackle the much more difficult step of introducing the site table. That meant a major overhaul of the table structure and a significant change/refactoring of the existing code and associated tests. After a couple of weeks of hard work this step was finally done and the site table came to life. That allowed us to rethink the way the risk calculators were working: it was now possible to remove the aggregation by location performed in the database, since the risk calculators could just retrieve the data for the site of interest and aggregate the arrays in code, in the worker nodes, without stressing the database, which was our real bottleneck.
In other words, it was now possible to solve most of our problems in a single step. Only the GMF export problem remained. This was particular annoying: now that all cores were working at 100%, we could run a computation in few minutes and there we had to wait several hours or days to export the results: in several cases it was actually impossible to get them, because of the terrible performance. The problem what that the table structure designed for the risk, was far for being ideal for the hazard export procedure, so we had to change it. A lot of time was spent in optimizing the table structure for the export without losing anything in performance on the risk side. Fortunaly, our efforts were coronated by a substantial success: we got at the same time enormous speedups in the export (100 times faster in a computation for the Bosphorus, passing from 80 hours to 19 minutes) and good speedups even in the risk side (50% faster in retrieving and aggregating the ground motion values).
Now we were ready to release the first version of the engine.
Appendix: a picture is worth a thousand words
For the curious readers, here I will report a picture for case study we analyzed in detail.
The plot below shows the assets in Miriam’s island and their association to the pre-computed hazard sites (click here to see it in regular size):
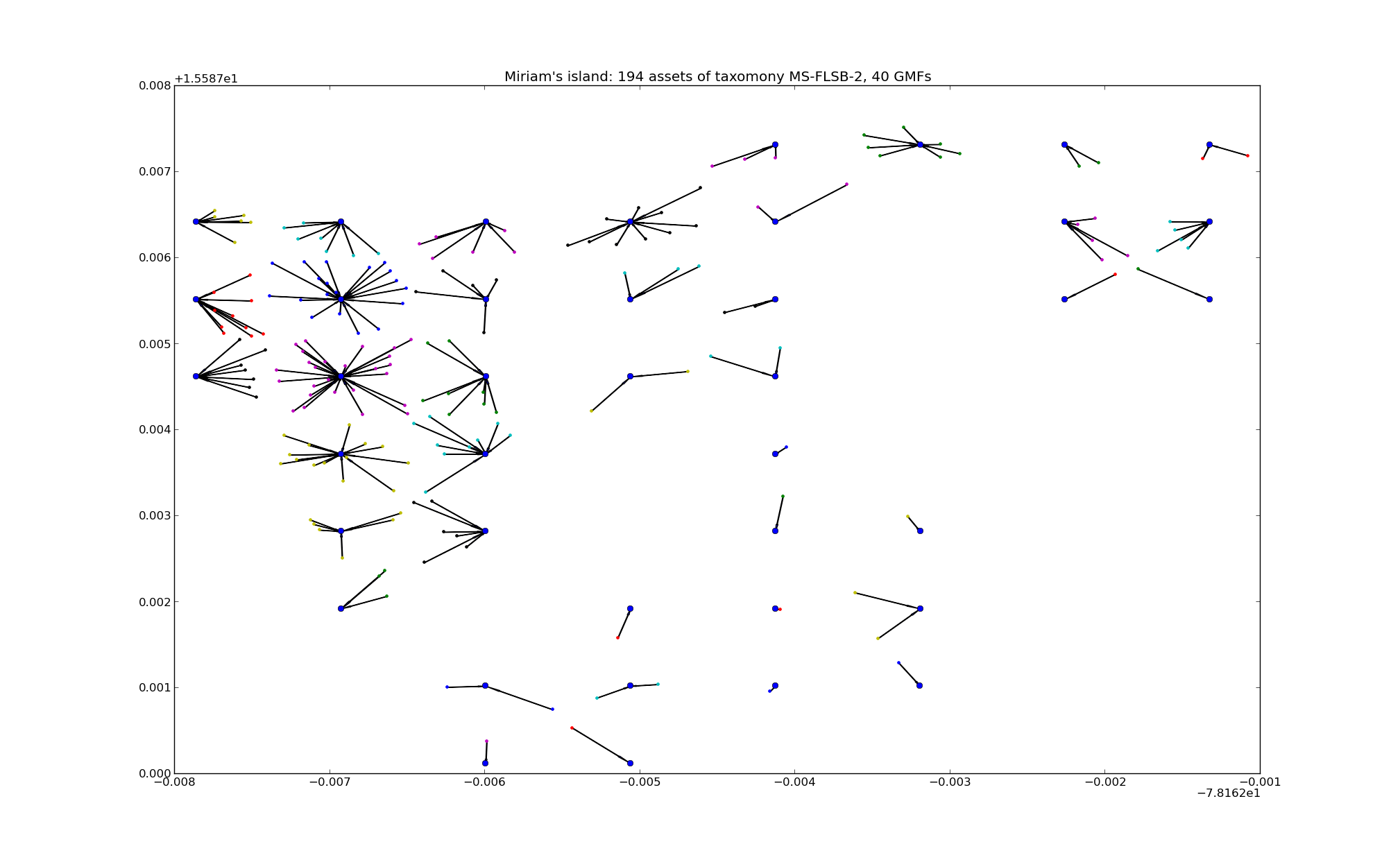
In total we have nearly 6,000 assets, but for the sake of the picture, I have only plotted 194 of them, for a specific taxonomy. Clustering together the assets close to the same hazard site make it possible a substantial optimization: instead of retrieving from the database large arrays several times (once per asset) for all the assets close to the same site we retrieve the ground motion values only once. That optimization solved the memory and performance issue we had in the risk calculator.